Note: We have had trouble performing this procedure using Microsoft's internet explorer. This download procedure still works with the Firefox, http://www.mozilla.com/, browser.
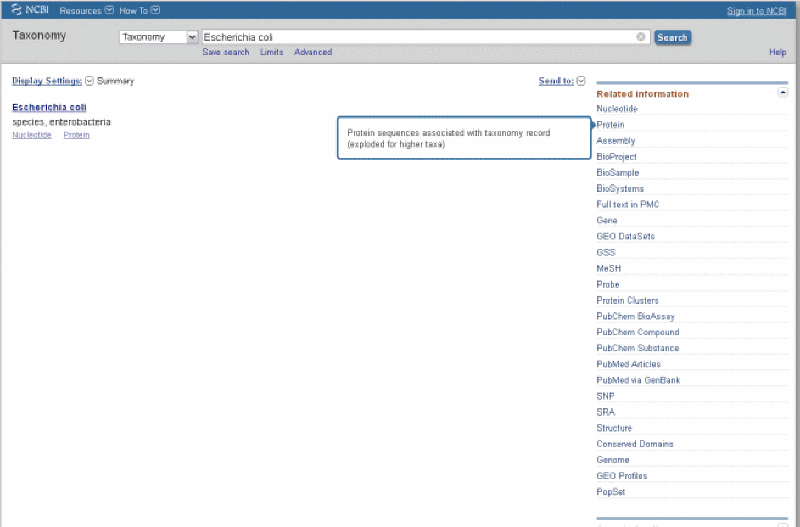
From The NCBI Home page http://www.ncbi.nlm.nih.gov/ select taxonomy and enter the organism, in this case Escherichia coli, and then press the "Search" button, see Figure 1.
Figure 1.
The resulting page is shown in Figure 2 below. Click on the protein link to list all E. Coli proteins in the NCBI repository.
Figure 2.
The result will be a list of all proteins in HTML format, see figure 3. Click on the "Send to" menu and select "File." Most MS search engines use files in FASTA format, so choose FASTA as the format, then click on the "Create File" button.
Figure 3.
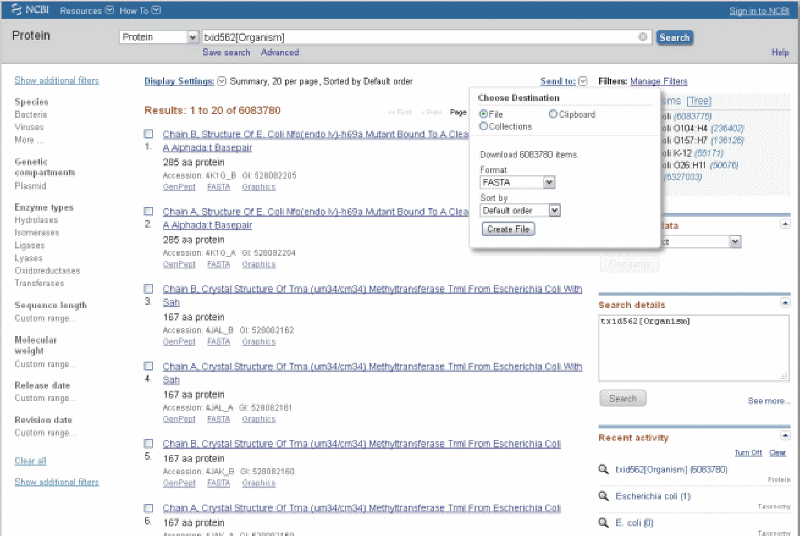
Figure 4 shows the dialog box that pops up. Click on "Save File" and click on "OK" and the file will begin to download to your computer. Depending on the organism this could take a while.
Figure 4.
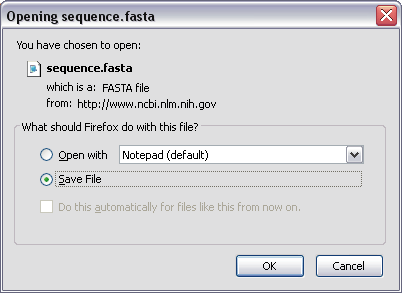
Figure 5. shows what the FASTA file will look like if you were to open it a simple text editor. It is basically a flat text file that can be searched by most of the MS sequence database search utilities.
Figure 5.

Thanks to NCBI, now you can create accurate, and specific subset databases that you can search with mass spectrometry data. This is especially important when searching nucleotide databases since they can be very large.
---
THE END
e-mail the webmaster@ionsource.com
with all inquiries
home
| terms of use
(disclaimer)
Copyright © 2000-2016 IonSource, LLC All rights reserved.
Last updated:
Tuesday, January 19, 2016 02:49:07 PM